Site Reliability Engineer (SRE)
Skills
About This Role
About the Role
We are looking for a Site Reliability Engineer (SRE) with solid experience running production systems and working closely with development teams.
The ideal candidate is comfortable with Linux, containers, Kubernetes, and CI/CD pipelines, and has a strong focus on reliability, monitoring, and incident handling.
You will help keep our services stable, observable, and scalable while collaborating with engineers across the stack.
Responsibilities
- Operate and maintain production systems with a focus on reliability, availability, and performance.
- Work with Docker and Kubernetes to deploy, update, and troubleshoot services.
- Configure and optimize Kubernetes resources (pods, deployments, services, ingress, config maps, secrets, etc.).
- Implement and maintain monitoring, logging, and alerting for applications and infrastructure.
- Build and improve CI/CD pipelines in collaboration with development and DevOps teams.
- Create and maintain dashboards for key service metrics (latency, error rate, throughput, resource usage).
- Participate in incident response: investigate issues, identify root cause, and propose fixes and improvements.
- Work closely with backend developers to improve service reliability, resilience, and observability.
- Contribute to capacity planning and performance tuning of services and infrastructure.
- Automate repetitive operational tasks using scripts or small tools.
- Document runbooks, procedures, and best practices for operating services in production.
Must-Have Qualifications
- 3–5 years of professional experience in an SRE, DevOps, or infrastructure-focused engineering role.
- Strong understanding of Linux systems (shell, processes, networking, permissions, logs).
- Hands-on experience with Docker and Kubernetes in real environments.
- Practical experience with:
- o Kubernetes deployments, services, ingress, config maps, and secrets o Basic troubleshooting inside a cluster (pods failing, crashes, restarts, resource issues)
- Experience with monitoring and logging tools (e.g., Prometheus, Grafana, ELK/EFK, Application Insights, or similar).
- Experience with CI/CD pipelines (Azure DevOps, GitHub Actions, GitLab CI, Jenkins, or similar).
- Ability to read and modify pipeline definitions and understand build test deploy flows.
- Basic programming/scripting skills in at least one language (e.g., Python, Bash, PowerShell, Go, etc.).
- Understanding of core reliability concepts such as SLIs, SLOs, uptime, latency, and availability.
- Experience troubleshooting production issues using logs, metrics, and dashboards.
- Good communication skills and ability to collaborate with developers, QA, and product teams.
Nice-to-Have
- Experience with at least one major cloud platform (Azure, AWS, Alibaba Cloud, or GCP).
- Experience with infrastructure as code (Terraform, Bicep, Pulumi, Helm, etc.).
- Experience with ingress controllers, API gateways, or service mesh.
- Familiarity with security best practices (secrets management, TLS/certificates, RBAC on Kubernetes or cloud).
- Experience participating in on-call rotations and using incident management tools (PagerDuty, Opsgenie, etc.).
- Experience contributing to post-incident reviews and implementing follow-up improvements.
Experience
3–5 years
Your resume, rewritten
for this exact role.
Sign up free — Base Career tailors your CV to this job description in 60 seconds.
01 / 05
Resume Tailored to This Job
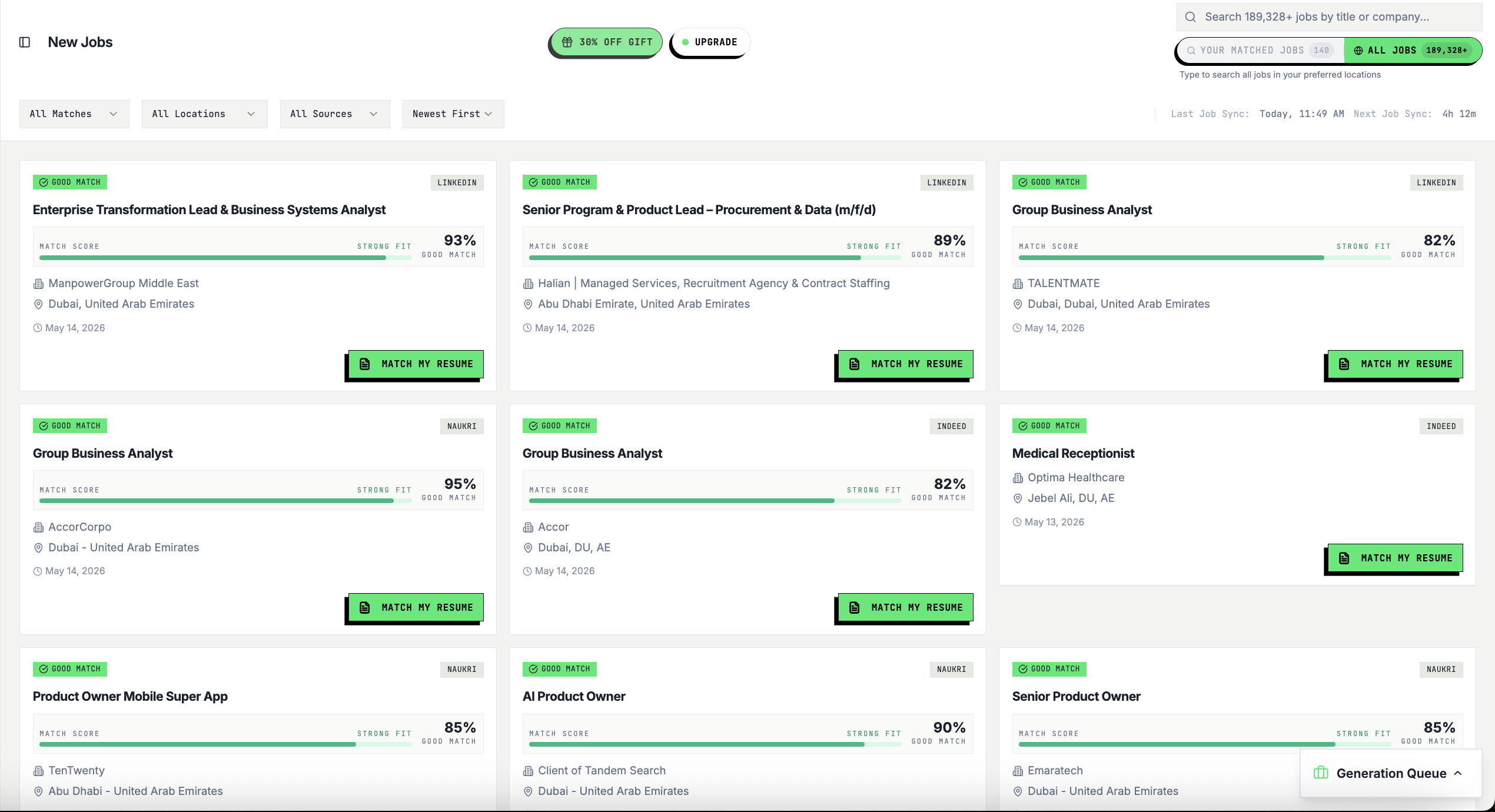
Your keywords, structure, and story — rewritten to match this exact role and pass ATS filters.
Free · No card · 60 seconds
02 / 05
Cover Letter for This Role, Done

Job-specific cover letters written in Gulf professional tone — ready in seconds, not hours.
Free · No card · 60 seconds
03 / 05
See How Well You Fit This Role
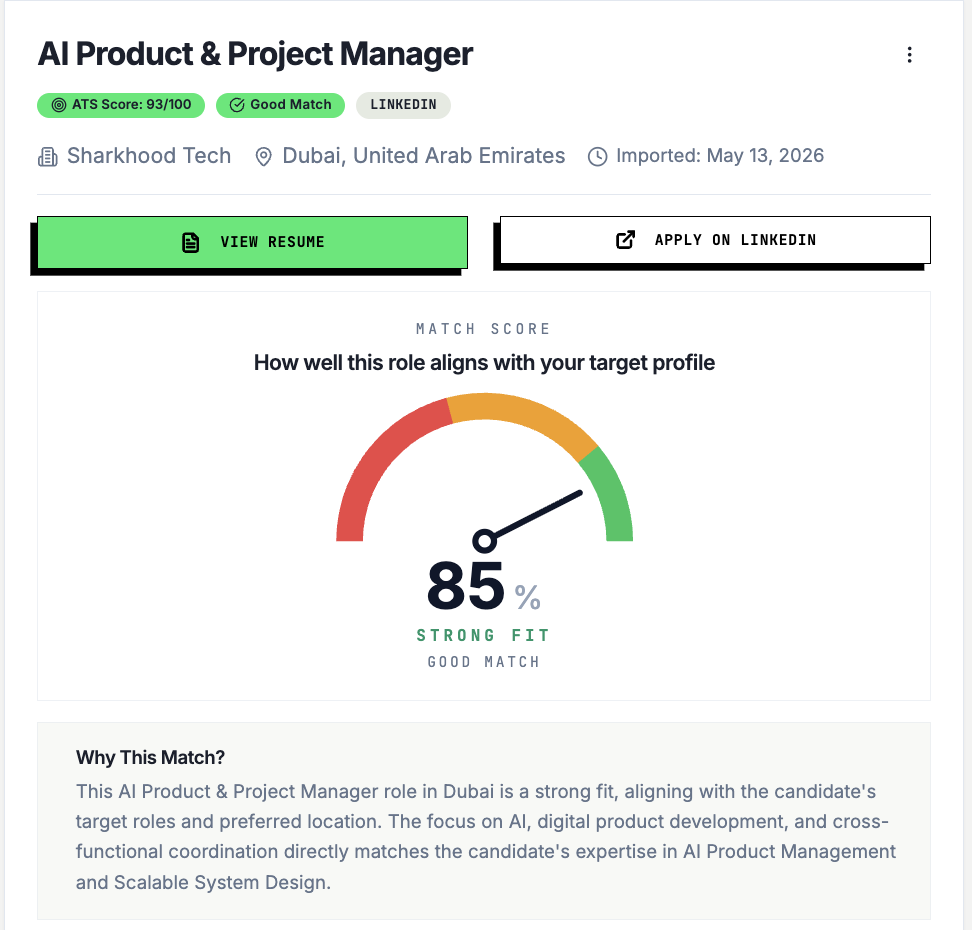
AI match score with clear reasons — know your fit before investing time in the application.
Free · No card · 60 seconds
04 / 05
Apply in One Click
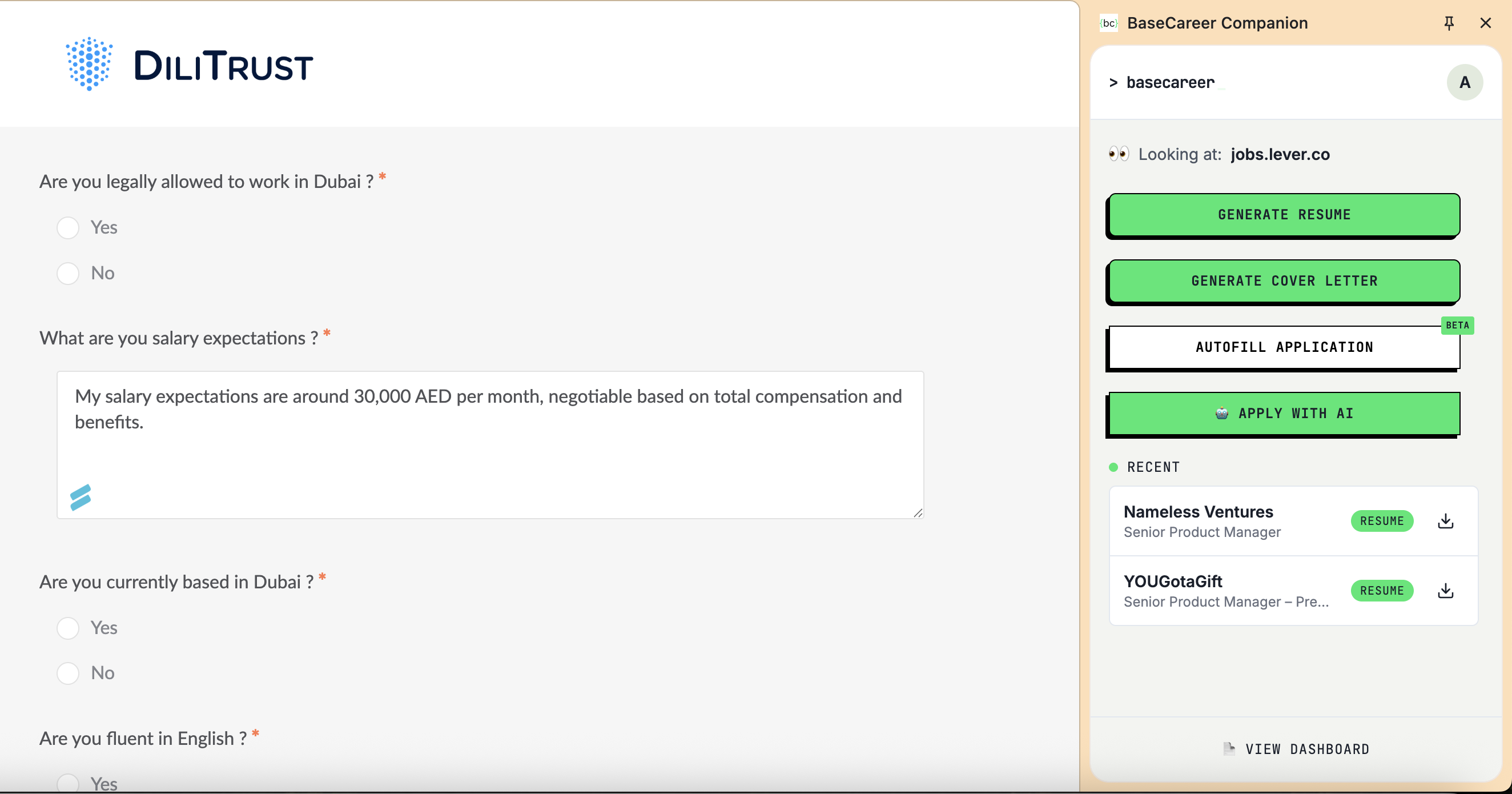
Autofill any application form on Workday, LinkedIn, Bayt, Greenhouse — with your tailored content.
Free · No card · 60 seconds
05 / 05
Track It. Follow Up at the Right Time.
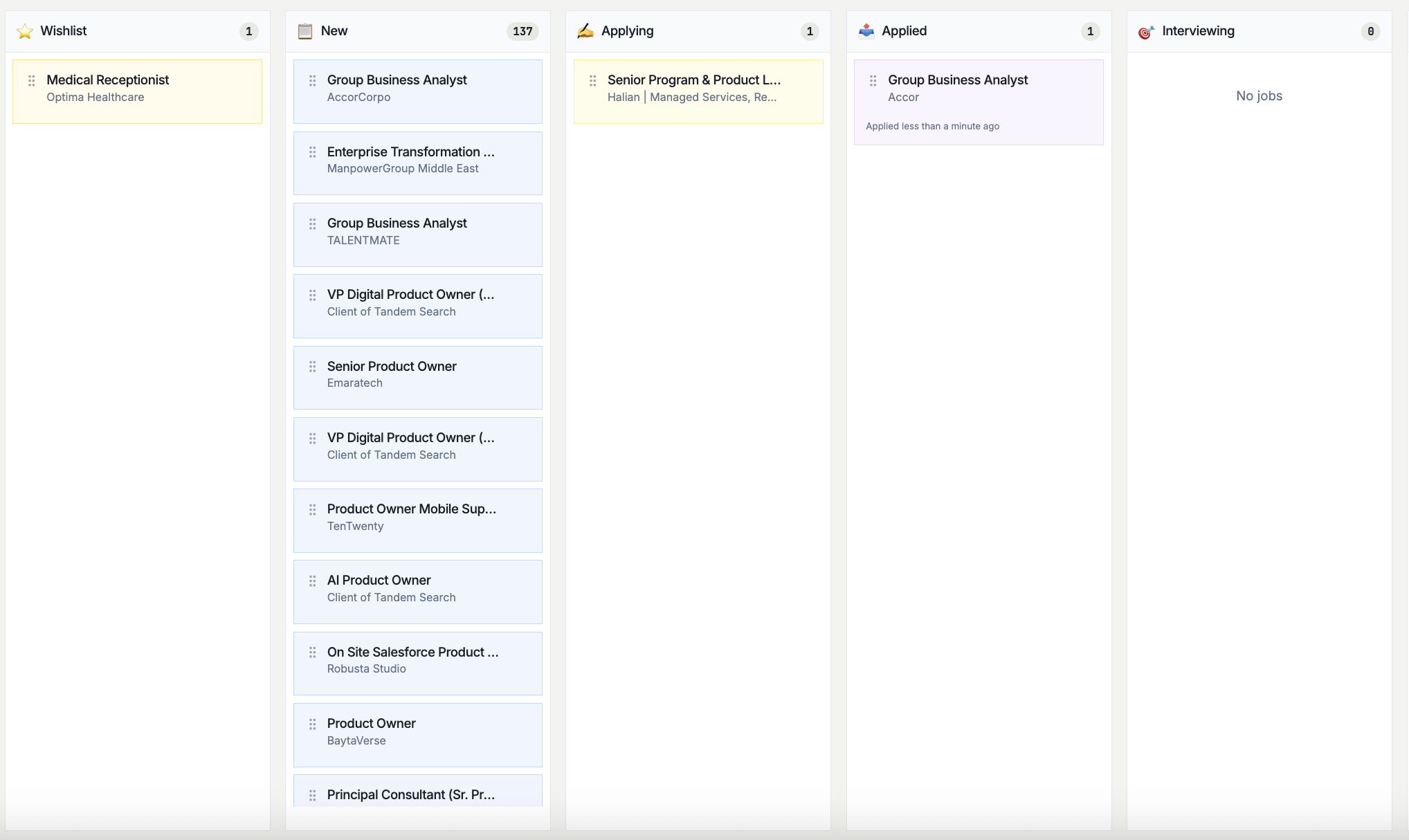
Visual pipeline for every application with AI-timed follow-up reminders so nothing slips.
Free · No card · 60 seconds
Similar Jobs
Site Reliability Engineer
S2 Global · Riyadh
Overview S2 Global is seeking a skilled and motivated Site Reliability Engineer (SRE) to implement, maintain, and support deployments of our CertScan platform. As part of our systems engineering team, you will design and
Skills
1 weeks ago
Apply Now↗Apply Now ↗Site Reliability Engineering Manager
Lucid Motors Middle East · Riyadh
Leading the future in luxury electric and mobility At Lucid, we set out to introduce the most captivating, luxury electric vehicles that elevate the human experience and transcend the perceived limitations of space, perf
Skills
1 weeks ago
Apply Now↗Apply Now ↗Site Reliability Engineering Manager
Lucid Motors · Riyadh
Lead Site Reliability Engineering initiatives, ensuring cloud service reliability, performance, and team management while utilizing Kubernetes, Terraform, and incident management.
Skills
1 weeks ago
Apply Now↗Apply Now ↗Infrastructure & Site Reliability Engineer – Datacentre AI Engineering - Riyadh, KSA
Qualcomm · Riyadh
Company Qualcomm Middle East Information Technology Company LLC Job Area Engineering Group, Engineering Group > Software Test Engineering General Summary About Us Qualcomm is growing its presence in Riyadh and is hiring
Skills
2 weeks ago
Apply Now↗Apply Now ↗Nutanix AI Site Reliability Lead Engineer
emagine · Riyadh
Nationality: Saudi Nationals only We are seeking an experienced Site Reliability Lead Engineer to act as the on-site technical lead for Nutanix AI infrastructure environments. The role is responsible for driving reliabil
Skills
3 weeks ago
Apply Now↗Apply Now ↗AI Infrastructure Nutanix Site Reliability Engineer
emagine · Riyadh
Job Title: AI Infrastructure Nutanix Site Reliability Engineer Location: Saudi Arabia Nationality: Saudi Nationals only Experience: 5+ years Job Overview: We are seeking an experienced AI Infrastructure Site Reliability
Skills
3 weeks ago
Apply Now↗Apply Now ↗Site Reliability Engineering Officer
Takamol Holding · Riyadh
Job Description Job description : Provide support for application incidents across digital platforms, working closely with Platform Engineering, Application Development, and customer support teams to ensure timely resol
Skills
3 weeks ago
Apply Now↗Apply Now ↗Site Reliability Engineer - Observability
Mirai Arabian International Company Limited · Riyadh
Seeking a Site Reliability Engineer focused on observability, automation, and reliability for AI platforms, requiring strong coding and cloud automation skills.
Skills
1 months ago
Apply Now↗Apply Now ↗Site Reliability Engineer
D360 Bank · Saudi Arabia
Support and maintain services, design scalable systems, develop monitoring tools, and ensure reliability while collaborating with teams and automating tasks.
Skills
1 months ago
Apply Now↗Apply Now ↗2.2K+
Cover Letters & Follow-ups
1.8K+
Resumes Tailored
190.5K+
Jobs Tracked
Trusted by professionals at
Stop applying blindly.
Start getting hired.
Base Career automates the hardest parts of job searching — apply smarter, not harder.
AI Resume in 60s
Your resume rewritten for this exact role using the job description as the brief.
ATS-Optimized
Get past automated screening filters with the right keywords matched to each job.
Application Tracker
Track every job, follow-up, and interview in one visual kanban board.
Free plan · No credit card required