Site Reliability Engineer
Skills
About This Role
Company Overview
Open Innovation AI is a global technology company that specializes in developing advanced solutions for managing AI workloads.
Its flagship product, the Open Innovation Cluster Manager (OICM), orchestrates complex AI tasks efficiently across diverse infrastructures.
The platform is hardware-agnostic, optimized for various GPUs and accelerators hardware, and facilitates seamless integration and scalability for enterprise AI applications.
Open Innovation AI focuses on optimizing and simplifying AI workload management and making AI technologies accessible to organizations of all sizes.
With its innovative solutions, companies can reduce operational costs, accelerate time to value, and maximize their return on investment, ensuring that their AI strategies contribute directly to enhanced business outcomes.
Site Reliability Engineer
is responsible for supporting and maintaining Open Innovation AI Products and deployments across customer environments, including secure and isolated on-premises infrastructures.
This role requires strong troubleshooting skills across hardware, Linux OS, Kubernetes, middleware, and application layers.
The engineer is expected to diagnose and resolve technical incidents, applying deep product knowledge and strong analytical skills to restore service availability.
The role requires solid understanding of operational processes such as Incident, Change, and Problem Management, along with a thorough grasp of the product architecture and how customers use it in production environments.
Role Responsibilities
- Experienced in Customer production environment deployments, mostly restricted connectivity and air gapped
- Involves ensuring availability, upgrades, stability of end-to-end AI platforms and solutions
- Diagnose and resolve incidents across hardware, Linux OS, Kubernetes clusters, containerized services, middleware, and platform components.
- Perform detailed analysis of logs, system behavior, and application output to identify root causes and restore service functionality.
- Review, validate, and execute approved changes following Change Management procedures, including system updates, configuration adjustments, and component upgrades.
- Maintain a strong understanding of the OICM and other OI product’s architecture, its services, dependencies, and typical customer usage patterns.
- Collaborate with L1 and Service Desk teams by providing technical guidance, clarifying issue details, and ensuring accurate ticket triage.
- Escalate complex, code-level or product-defect issues to L3 with complete diagnostic in-formation and structured analysis.
- Conduct on-site platform health assessments, validating Kubernetes cluster status, ser-vice integrity, system resources, and overall environment readiness.
- Work closely with the Systems Engineering team to analyze and resolve performance is-sues across compute, storage, networking, and Kubernetes layers, and ensure that identified optimizations are reflected in the product and operational practices.
- Update and maintain technical documentation including SOPs, runbooks, troubleshooting steps, and known-issue guides.
- Participate in post-incident reviews, contributing technical insights and recommending improvements to prevent recurrence.
- Ensure all activities adhere to established Incident, Change, and Problem Management processes.
Required experience & Qualification
- Bachelor’s degree in computer science, Information Technology, Engineering, or a related field.
- 4–7 years of experience in SRE, DevOps, Infrastructure Operations, or Platform Engineering roles within on-prem or secure environments.
- Strong proficiency in Linux system administration, including troubleshooting, log analysis, service management, and performance tuning.
- Hands-on experience with Kubernetes, container runtimes, and distributed systems deployed in on-prem environments.
- Solid understanding of compute, storage, networking, and virtualization layers relevant to enterprise installations.
- Practical experience with middleware and data-layer components such as Kafka, Redis, PostgreSQL, or similar technologies used in distributed on-prem environments.
- Strong understanding of ITIL-aligned and experience operating within structured operational frameworks.
- Ability to diagnose complex issues across multiple layers of the stack.
- Experience working in secure, restricted, or isolated environments is an advantage.
- Excellent analytical skills, communication abilities, and a methodical approach to troubleshooting.
- Ability to produce clear technical documentation, including SOPs, runbooks, and investigation reports.
- Certifications such as RHCSA/RHCE, CKA/CKAD/CKS.
Your resume, rewritten
for this exact role.
Sign up free — Base Career tailors your CV to this job description in 60 seconds.
01 / 05
Resume Tailored to This Job
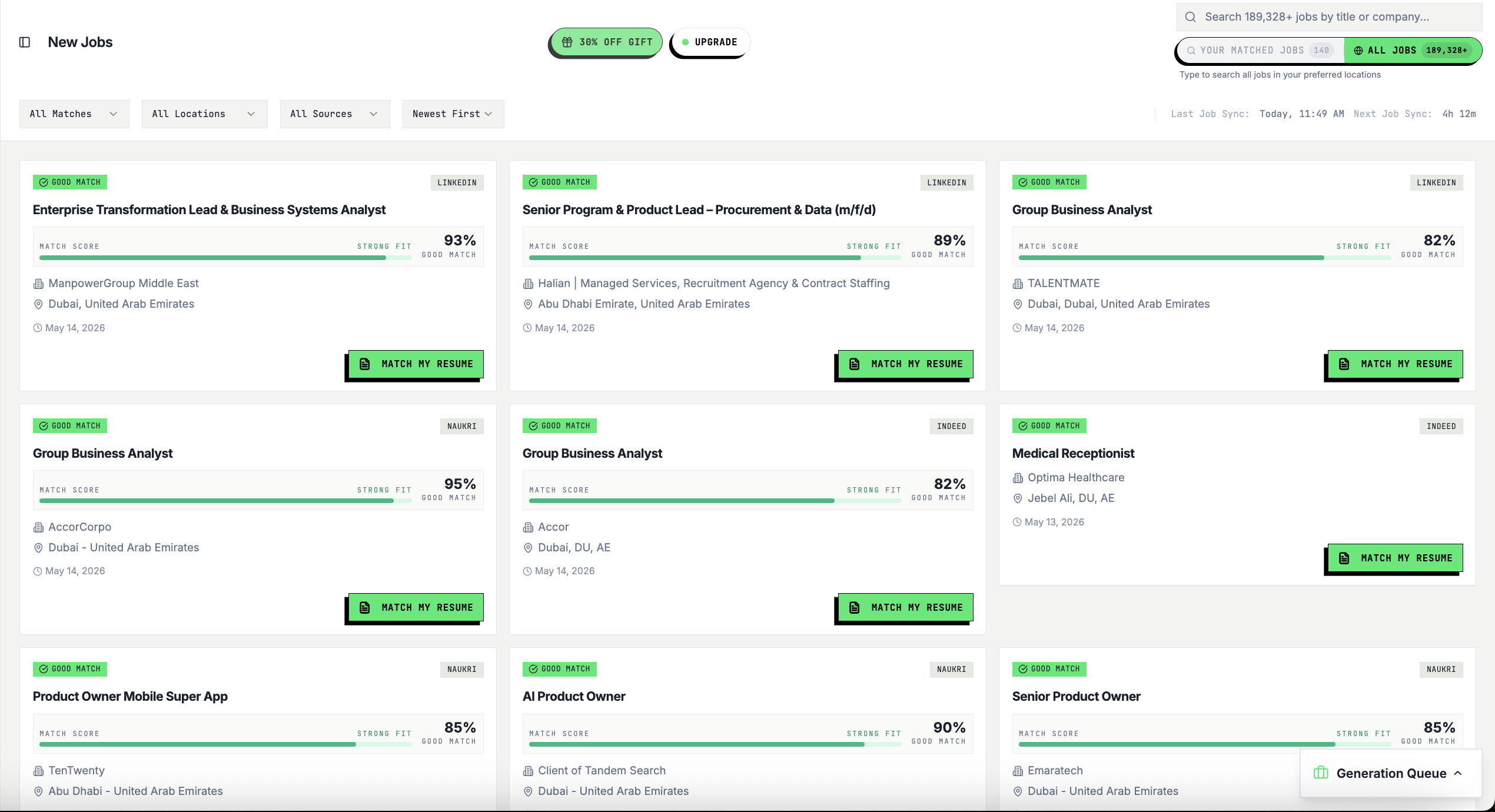
Your keywords, structure, and story — rewritten to match this exact role and pass ATS filters.
Free · No card · 60 seconds
02 / 05
Cover Letter for This Role, Done

Job-specific cover letters written in Gulf professional tone — ready in seconds, not hours.
Free · No card · 60 seconds
03 / 05
See How Well You Fit This Role
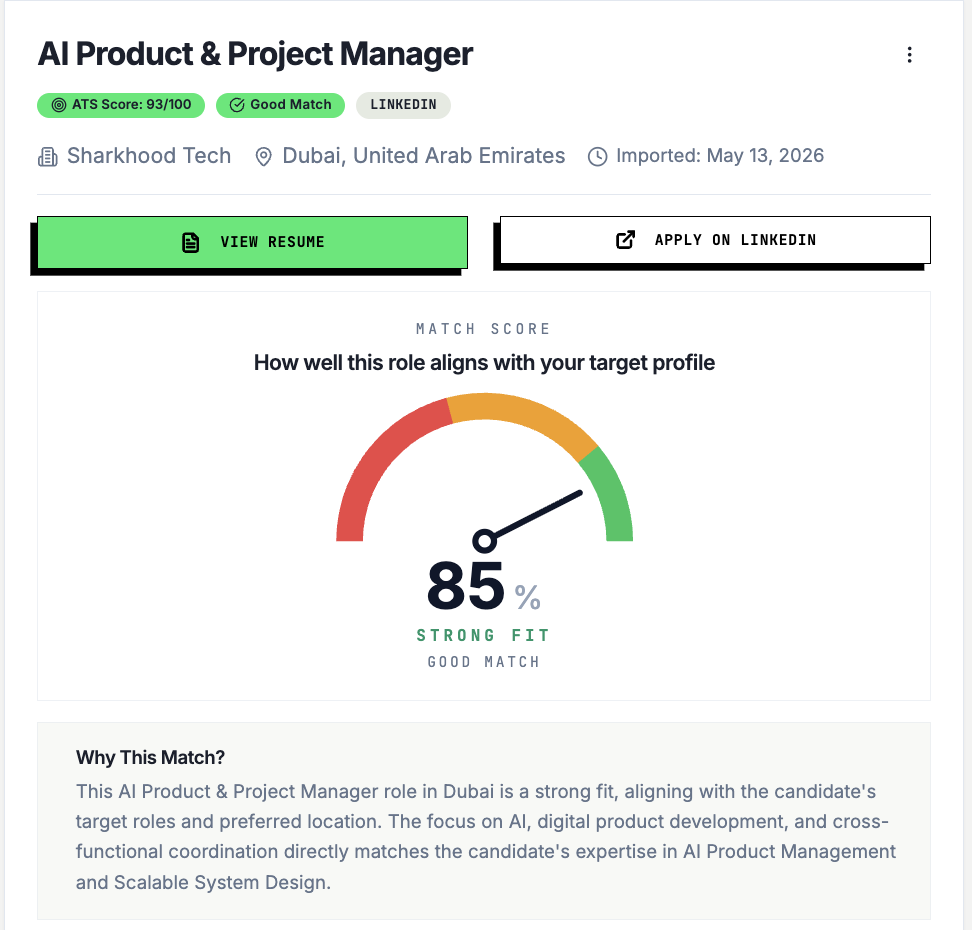
AI match score with clear reasons — know your fit before investing time in the application.
Free · No card · 60 seconds
04 / 05
Apply in One Click
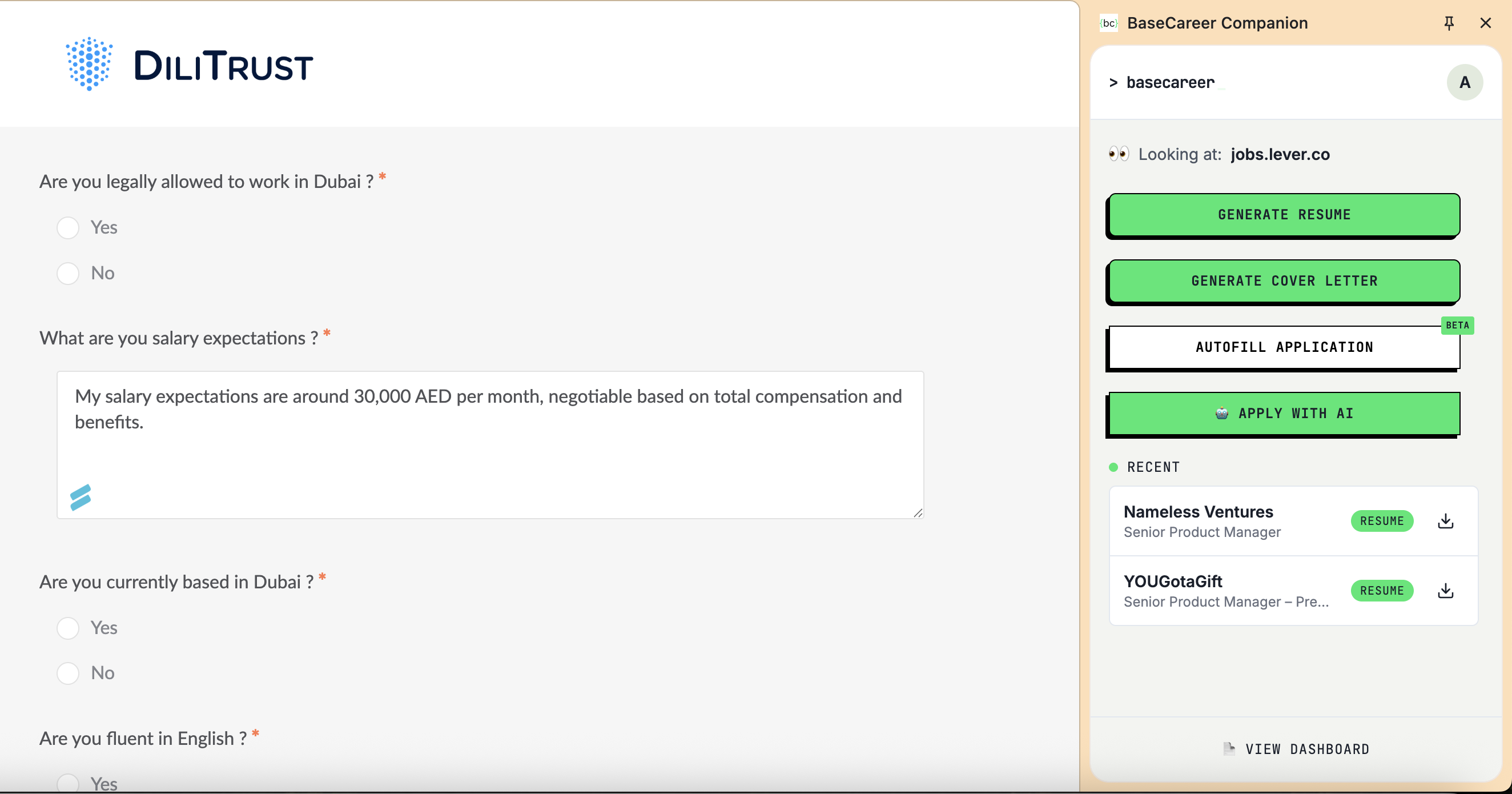
Autofill any application form on Workday, LinkedIn, Bayt, Greenhouse — with your tailored content.
Free · No card · 60 seconds
05 / 05
Track It. Follow Up at the Right Time.
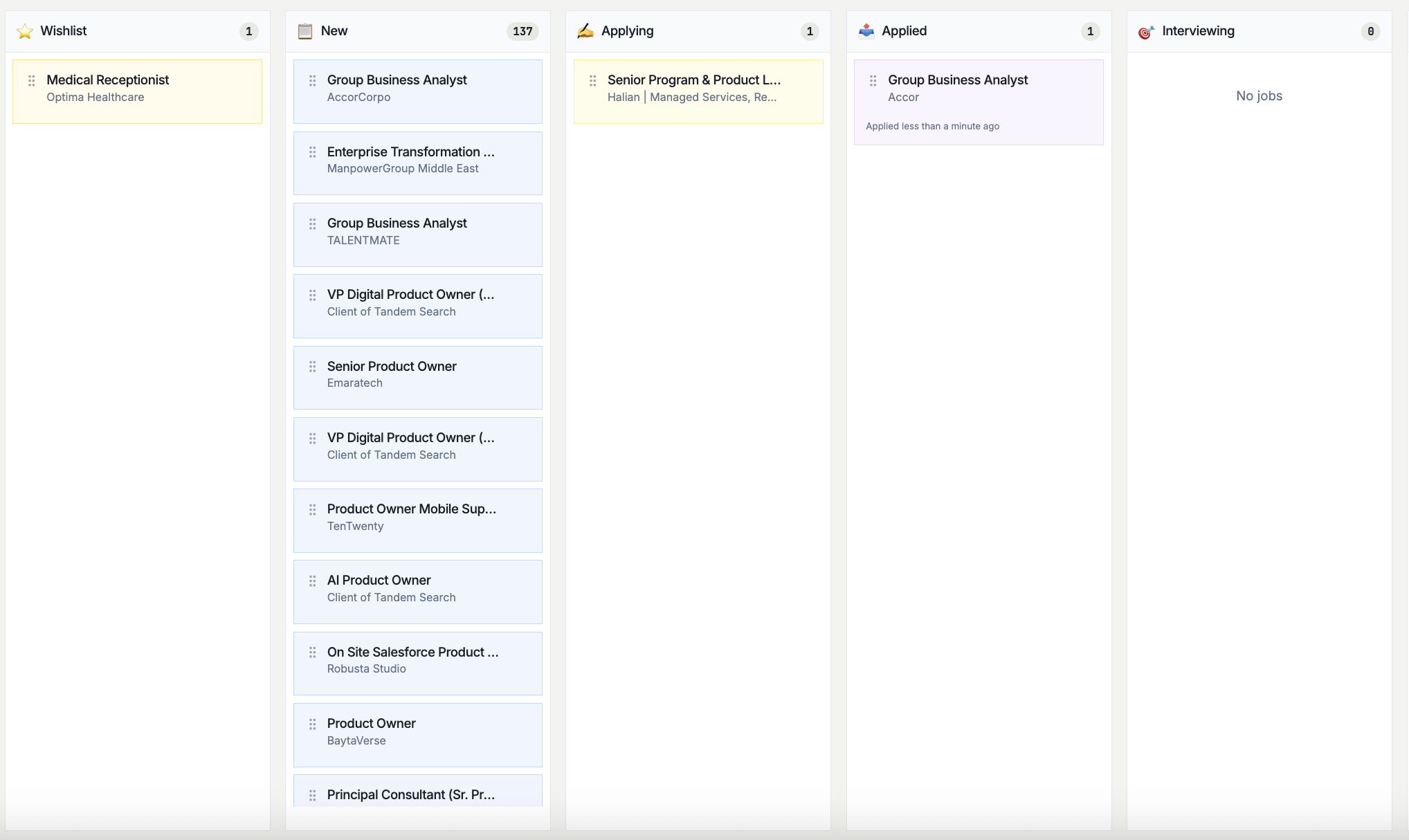
Visual pipeline for every application with AI-timed follow-up reminders so nothing slips.
Free · No card · 60 seconds
Similar Jobs
Software Engineer (DevOps) - Site Reliability
Revolut ·
About Revolut People deserve more from their money. More visibility, more control, and more freedom. Since 2015, Revolut has been on a mission to deliver just that. Our powerhouse of products — including spending, saving
Skills
Site Reliability Engineer
Socium - Teams Done Differently · Abu Dhabi
Job Title: Senior Site Reliability Engineer (SRE) Location: Abu Dhabi, UAE Work Setup: Onsite Contract Duration: 6 Months Rolling Contract General Description We are seeking a highly experienced Senior Site Reliability E
Skills
Yesterday
Apply Now↗Apply Now ↗Site Reliability Engineer (SRE) (m/f/d)
Halian | Managed Services, Recruitment Agency & Contract Staffing · Abu Dhabi Emirate
Site Reliability Engineer (SRE) Role Overview We are seeking a Site Reliability Engineer to ensure the resilience, performance, and production readiness of cloud-based AI systems. Key Responsibilities Implement resilien
Skills
Yesterday
Apply Now↗Apply Now ↗Senior Site Reliability Engineer
Core42 · Abu Dhabi Emirate
Senior Site Reliability Engineer, Core42 – Abu Dhabi, UAE About Us Core42, a leader in AI-powered cloud and digital infrastructure, is driving transformative technology solutions globally. Leveraging advanced resources a
Skills
Yesterday
Apply Now↗Apply Now ↗Site Reliability Engineer
Socium - Teams Done Differently · Abu Dhabi
Job Title: Senior Site Reliability Engineer (SRE) Location: Abu Dhabi, UAE Work Setup: Onsite Contract Duration: 6 Months Rolling Contract General Description We are seeking a highly experienced Senior Site Reliability E
Skills
3 days ago
Apply Now↗Apply Now ↗Site Reliability Engineer (SRE) (m/f/d)
Halian | Managed Services, Recruitment Agency & Contract Staffing · Abu Dhabi Emirate
Site Reliability Engineer (SRE) Role Overview We are seeking a Site Reliability Engineer to ensure the resilience, performance, and production readiness of cloud-based AI systems. Key Responsibilities Implement resilien
Skills
3 days ago
Apply Now↗Apply Now ↗Site Reliability Engineer (SRE)
D4 Insight · Abu Dhabi
Location: Abu Dhabi Experience: 5–8 Years ### Role Overview: We are seeking a highly motivated Site Reliability Engineer (SRE) to ensure the reliability, scalability, and performance of enterprise applications and cloud
Skills
3 days ago
Apply Now↗Apply Now ↗Site Reliability Engineer (SRE)
D4 Insight · Abu Dhabi
Location: Abu Dhabi Experience: 5–8 Years Role Overview We are seeking a highly motivated Site Reliability Engineer (SRE) to ensure the reliability, scalability, and performance of enterprise applications and cloud infra
Skills
3 days ago
Apply Now↗Apply Now ↗Principal Site Reliability Engineer
Core42 · Abu Dhabi Emirate
About Us Core42, a leader in AI-powered cloud and digital infrastructure, is driving transformative technology solutions globally. Leveraging advanced resources and partnerships, Core42 empowers clients to harness sovere
Skills
4 days ago
Apply Now↗Apply Now ↗2.2K+
Cover Letters & Follow-ups
1.8K+
Resumes Tailored
190.5K+
Jobs Tracked
Trusted by professionals at
Stop applying blindly.
Start getting hired.
Base Career automates the hardest parts of job searching — apply smarter, not harder.
AI Resume in 60s
Your resume rewritten for this exact role using the job description as the brief.
ATS-Optimized
Get past automated screening filters with the right keywords matched to each job.
Application Tracker
Track every job, follow-up, and interview in one visual kanban board.
Free plan · No credit card required