Lead Linux Platform Engineer
Skills
About This Role
About the role
- We run a fleet of 1000+ high-performance Linux workstations supporting engineering, ML, and research teams, and we’re investing in the platform that provisions, configures, secures, and maintains them at scale.
- We’re looking for a lead engineer to own that platform end to end, technically and architecturally.
- This is the first of several planned hires.
- You won’t just build the system; you’ll define how it’s built, make the foundational tooling decisions, set the engineering standards the rest of the team will work to, and help hire and grow that team.
- You’ll have significant autonomy and a corresponding level of ownership.
- The work spans configuration management (Puppet or a similar configuration management tool), network-based provisioning, fleet inventory, network access control integration, hardware lifecycle, and the security and operational tooling that keeps a large, heterogeneous workstation fleet consistent and reliable.
- This is a hands-on lead role: you’ll be in the code and on the architecture, not managing from a distance.
- These workstations support active research.
- Faculty and researchers depend on them for grant-funded, deadline-driven work, and they often have specific, non-negotiable technical requirements.
- A core part of this role is engaging directly with those researchers: understanding what their work actually needs, translating it into a sustainable platform, and weighing technical decisions against research priorities, funding constraints, and the disruption any change imposes on people with deadlines.
- What you’ll own :
- **Technical direction :**
- Set the architecture for fleet management: configuration management, provisioning, inventory, patching, network access, and security.
- Make and document the build-vs-buy and tooling decisions (provisioning platform, secrets management, observability stack), and own the tradeoffs.
- **The configuration management platform :**
- Own the Puppet (or OpenVox) codebase: module design, the role-and-profile pattern, Hiera data architecture, and the control repository.
- Establish the patterns the team will follow.
- **The provisioning pipeline :**
- Own bare-metal provisioning from network boot through to a fully configured machine: PXE/iPXE, unattended OS installation, and the handoff into configuration management.
- Design it to scale and to be operated by a team, not a hero.
- **Network access control integration :**
- Partner with the network and security teams to integrate the workstation fleet with NAC (802.1X).
- Own the endpoint side: supplicant configuration managed through Puppet, device certificate enrollment and lifecycle, and solving the provisioning-time access problem (provisioning VLANs, MAC Authentication Bypass, or equivalent) so bare machines can be imaged without compromising the access control posture.
- **Hardware lifecycle and support :**
- Own the hardware side of the fleet: define and maintain hardware tiers, validate new models and components (CPUs, GPUs, storage, peripherals) for Linux and driver compatibility, and automate firmware and BIOS management at scale.
- Manage vendor relationships, drive RMA and break-fix workflows, and own hardware refresh and lifecycle planning.
- **Fleet operations :**
- Own inventory and reporting (PuppetDB), patch management and update orchestration, drift detection, and the day-to-day reliability of the fleet.
- Balance security currency against the reality that these machines have users on them.
- **Security and compliance :**
- Own the security posture of the fleet, covering secrets management, host hardening, audit logging, compliance baselines, and the endpoint contribution to network access control, and make sure auditability is designed in rather than retrofitted.
- **Engineering standards :**
- Establish infrastructure-as-code discipline: Git as the single source of truth, change through review, CI/CD for infrastructure code, and no manual changes on hosts.
- Set the bar the team will hold.
- **Researcher engagement and requirements :**
- Work directly with faculty and research staff to understand their technical needs (software stacks, reproducibility requirements, performance characteristics) and turn those into platform capabilities.
- Translate between research requirements and what the platform can sustainably deliver, set expectations honestly, and make sure maintenance, patching, and change windows account for grant deadlines, publication cycles, and the cost of disrupting active work.
- **Team building :**
- Help define, hire, and onboard the next engineers on the team.
- Mentor them.
- Document the platform well enough that it doesn’t depend on any single person, including you.
- Required experience :
- 8+ years in Linux systems, infrastructure, or platform engineering, with a track record of owning systems at scale.
- Deep, hands-on expertise with a declarative configuration management tool in production. Puppet/OpenVox is strongly preferred; substantial Salt or Chef experience plus a clear willingness to lead in Puppet will be considered.
- Strong command of Linux at scale: package management, systemd, networking, storage, and kernel-level configuration.
Experience
- across both Debian-family (Ubuntu) and RHEL-family (Rocky) distributions preferred, including the differences in packaging, provisioning, and tooling between them.
- Experience designing or owning network-based provisioning: PXE/iPXE, TFTP, DHCP concepts, and unattended installation (autoinstall, kickstart, or preseed).
- Working knowledge of network access control: 802.1X, RADIUS concepts, supplicant configuration, and the operational challenges of authenticating a large endpoint fleet (including provisioning-time and break-glass scenarios).
- Hands-on experience managing physical hardware at scale: firmware/BIOS management, driver compatibility, and hardware troubleshooting across vendors.
- A demonstrated infrastructure-as-code mindset: Git-based workflows, code review, and CI/CD for infrastructure.
- Proficiency in at least one of Bash, Python, or Ruby, and the judgment to know when to script and when not to.
- Solid grounding in secrets management (HashiCorp Vault or similar) and secure credential handling.
- Working knowledge of system hardening and audit tooling: CIS benchmarks, SELinux/AppArmor, auditd.
- Evidence of technical leadership: setting architecture, making consequential tradeoffs, and bringing others along, whether or not you’ve held a “lead” title before.
- A track record of working directly with non-technical or differently-technical stakeholders: gathering requirements, managing expectations, and balancing competing priorities against operational and budget constraints.
- Strongly preferred :
- Experience operating fleets of 500+ Linux endpoints, particularly workstations rather than servers. They behave differently, and that difference matters.
- Hands-on production experience with Ubuntu and Rocky Linux specifically, including the practical implications of supporting both in one fleet (apt vs. dnf, autoinstall vs. kickstart, differing release and support lifecycles).
- High-performance computing exposure: GPU driver management (NVIDIA/CUDA, ROCm), NUMA, hugepages, CPU governors, and performance tuning.
- Hands-on experience with provisioning platforms (Foreman, Cobbler, MAAS) and a clear, opinionated view of their tradeoffs.
- Experience integrating endpoints with enterprise NAC platforms (Cisco ISE, Aruba ClearPass, or similar) and with certificate-based 802.1X.
- Firmware automation experience: vendor tooling (Dell, HP, Lenovo, Supermicro) and cross-vendor approaches such as fwupd/LVFS.
- Vendor management experience: working with hardware OEMs on enterprise accounts, validation programs, and support escalations.
- Observability at fleet scale: Prometheus, Grafana, centralized logging (Loki, ELK, or similar).
- CI/CD for infrastructure code: rspec-puppet, Litmus, PDK, or equivalents.
- Ansible experience, valuable for orchestration work and for making sound tooling decisions across paradigms.
- Inventory/CMDB systems (NetBox or similar).
- Networking fundamentals in a corporate environment: VLANs, DHCP relay, and the constraints these impose on provisioning and access control.
- Experience hiring, mentoring, or growing an engineering team.
- Experience supporting research, academic, or scientific computing environments, with familiarity with how research workflows, reproducibility needs, and grant or publication timelines shape platform decisions.
- What we’re looking for in a person
- This role rewards judgment as much as technical depth.
- The strongest candidates tend to :
- Think in desired state and reproducibility, and design systems a team can operate, not just an expert.
- Make decisions with incomplete information, document the reasoning, and revisit when facts change.
- Hold a clear technical opinion while genuinely engaging with the alternatives, including tools and approaches they didn’t choose.
- Work effectively across team boundaries, particularly with network and security teams, where this role’s success depends on partnership rather than control.
- Treat security and auditability as part of the design from day one.
- Communicate tradeoffs clearly to engineers, researchers, and non-technical stakeholders alike, and listen as well as they explain.
- Understand that the platform exists to serve the research, and weigh technical elegance against what actually helps faculty and researchers get their work done.
- Want to build something durable, and to build the team and documentation that keep it durable when they’re not in the room.
Your resume, rewritten
for this exact role.
Sign up free — Base Career tailors your CV to this job description in 60 seconds.
01 / 05
Resume Tailored to This Job
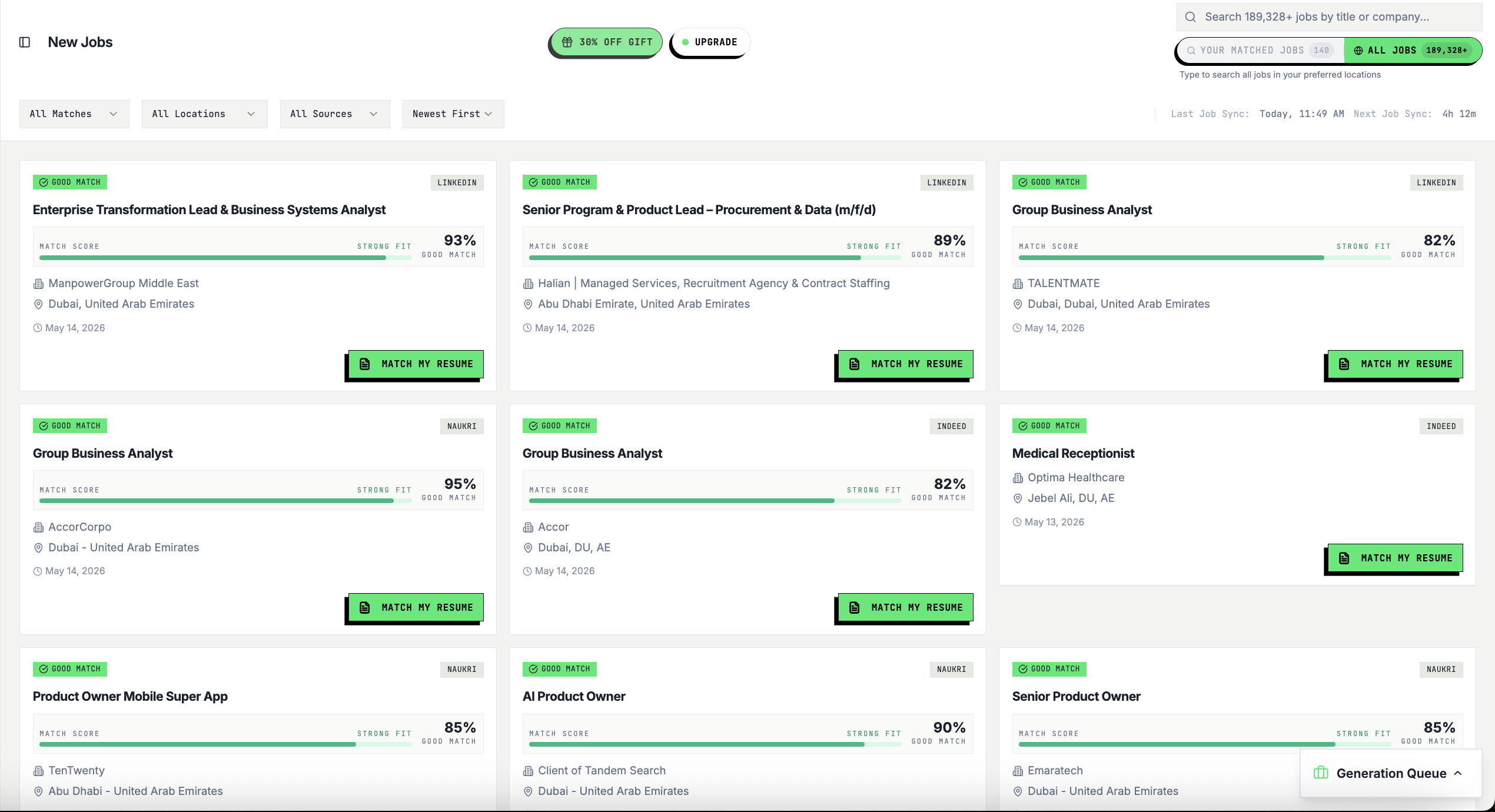
Your keywords, structure, and story — rewritten to match this exact role and pass ATS filters.
Free · No card · 60 seconds
02 / 05
Cover Letter for This Role, Done

Job-specific cover letters written in Gulf professional tone — ready in seconds, not hours.
Free · No card · 60 seconds
03 / 05
See How Well You Fit This Role
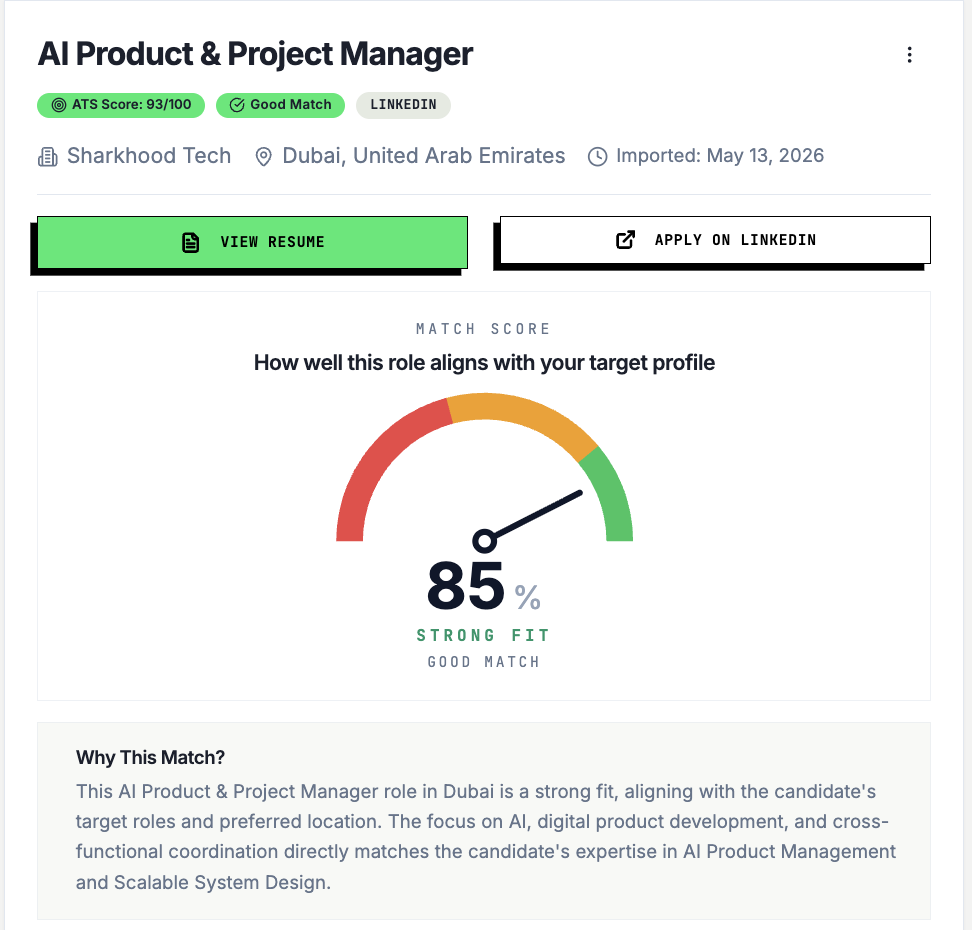
AI match score with clear reasons — know your fit before investing time in the application.
Free · No card · 60 seconds
04 / 05
Apply in One Click
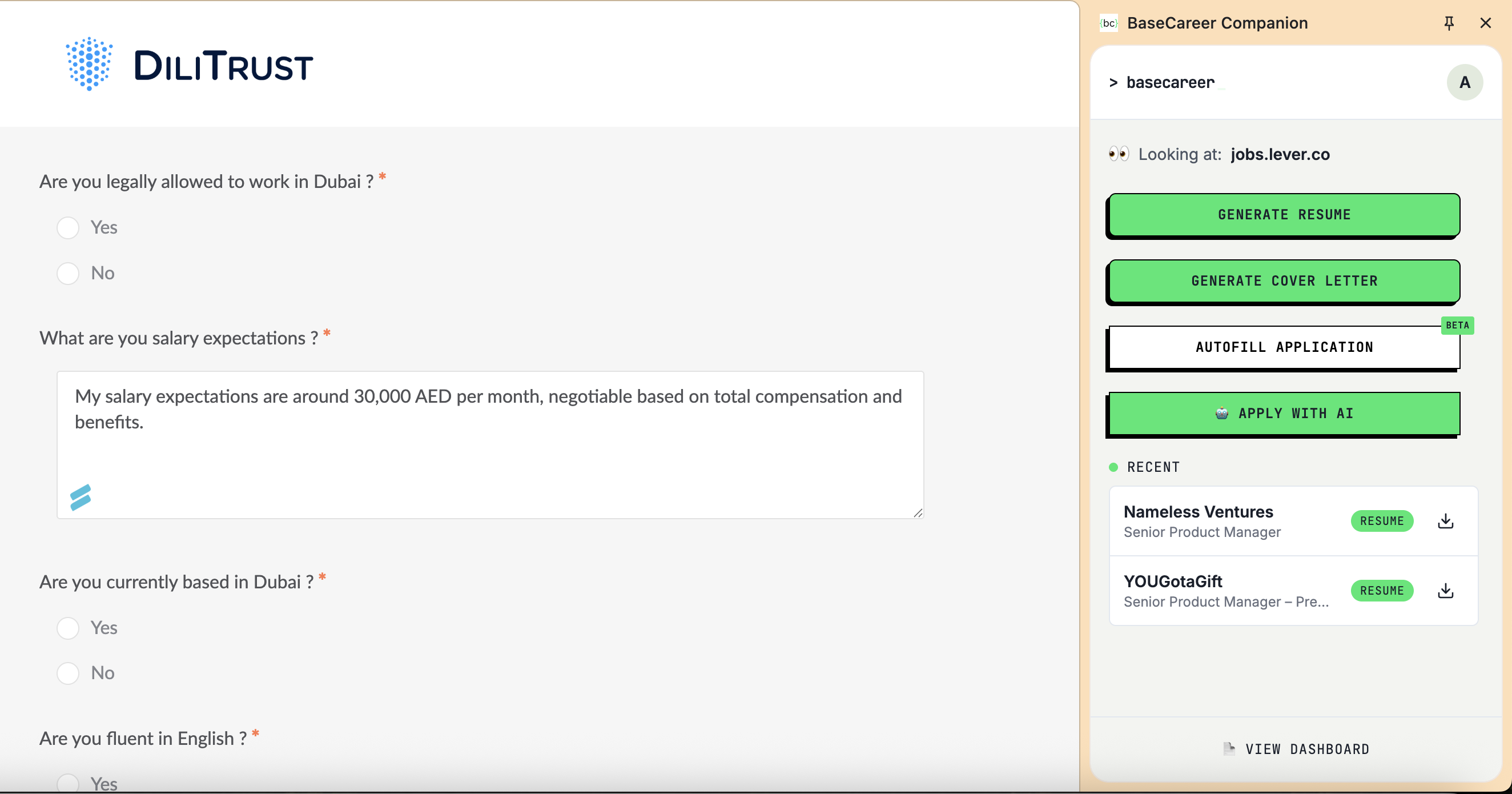
Autofill any application form on Workday, LinkedIn, Bayt, Greenhouse — with your tailored content.
Free · No card · 60 seconds
05 / 05
Track It. Follow Up at the Right Time.
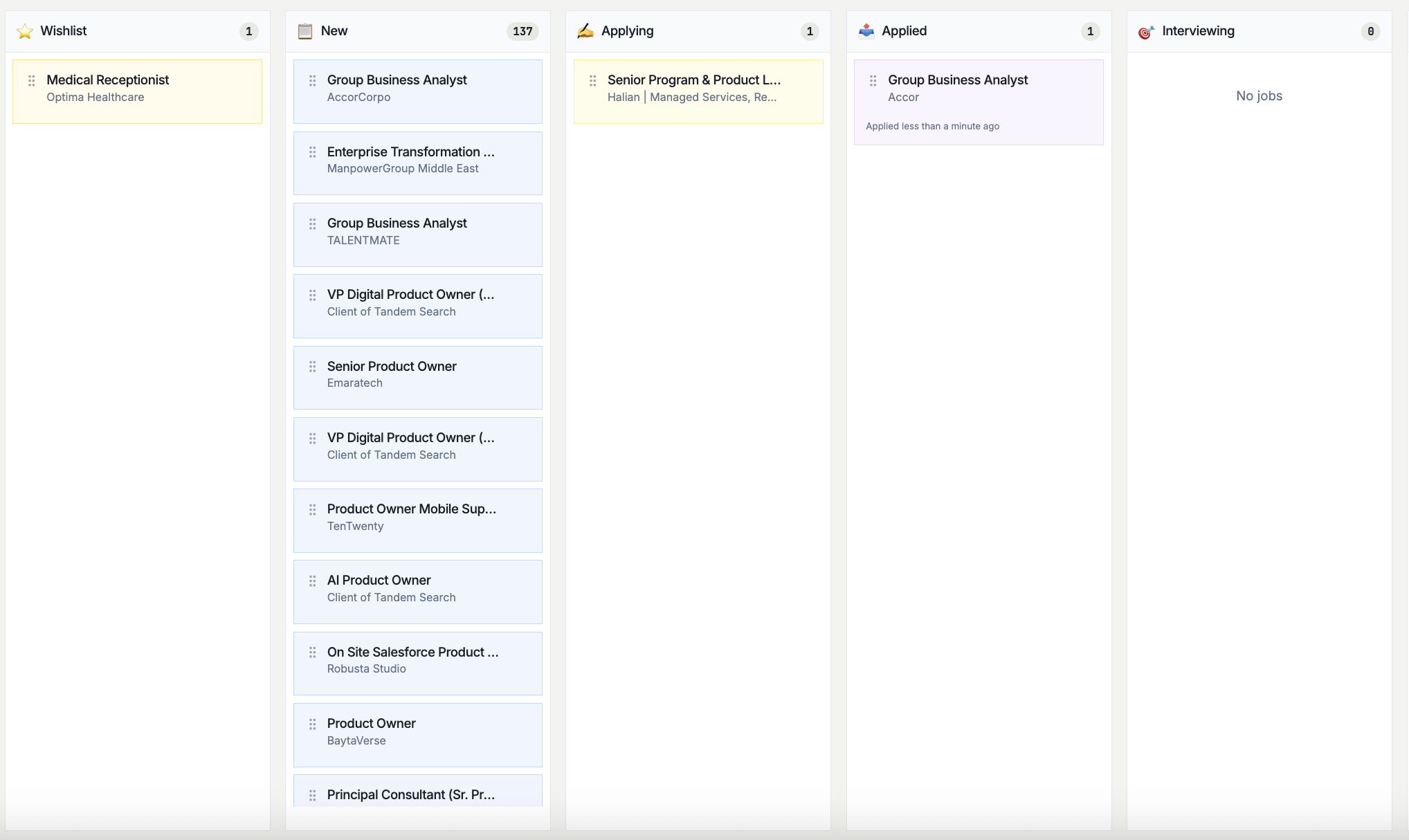
Visual pipeline for every application with AI-timed follow-up reminders so nothing slips.
Free · No card · 60 seconds
2.2K+
Cover Letters & Follow-ups
1.8K+
Resumes Tailored
190.5K+
Jobs Tracked
Trusted by professionals at
Stop applying blindly.
Start getting hired.
Base Career automates the hardest parts of job searching — apply smarter, not harder.
AI Resume in 60s
Your resume rewritten for this exact role using the job description as the brief.
ATS-Optimized
Get past automated screening filters with the right keywords matched to each job.
Application Tracker
Track every job, follow-up, and interview in one visual kanban board.
Free plan · No credit card required